SV2TEXT — 抖音收藏视频智能分析系统
让 AI 替你看视频——自动采集抖音收藏、智能过滤、逐帧分析,将 735 个碎片化短视频转化为可检索的结构化求职报告。
目录
背景与痛点
刷抖音已经成为我获取求职信息和 AI 前沿知识的主要方式。通勤、午休、睡前——每天随手收藏几十条”以后再看”的干货视频,面经、薪资爆料、内推渠道、Agent 开发教程、RAG 架构解析……但 735 个收藏躺在那里,真正点开看完的不到十分之一。
核心痛点:
- 收藏即遗忘:短视频平台没有”稍后阅读”功能,收藏夹沦为信息坟场
- 信息密度低:10 分钟视频的核心干货往往只有 2 分钟,大量时间浪费在开场白和引流话术
- 无法检索对比:视频内容不可搜索,无法快速定位特定企业、岗位或薪资信息
SV2TEXT 的核心思路很朴素——让 AI 替你看视频。它自动爬取抖音收藏、用 LLM 过滤无关内容、下载无水印视频,然后调用 Qwen 多模态模型逐帧分析,最终生成可直接查阅的结构化报告。以前需要花几十个小时看完的视频,现在花几分钟读一份报告就够了。
系统架构
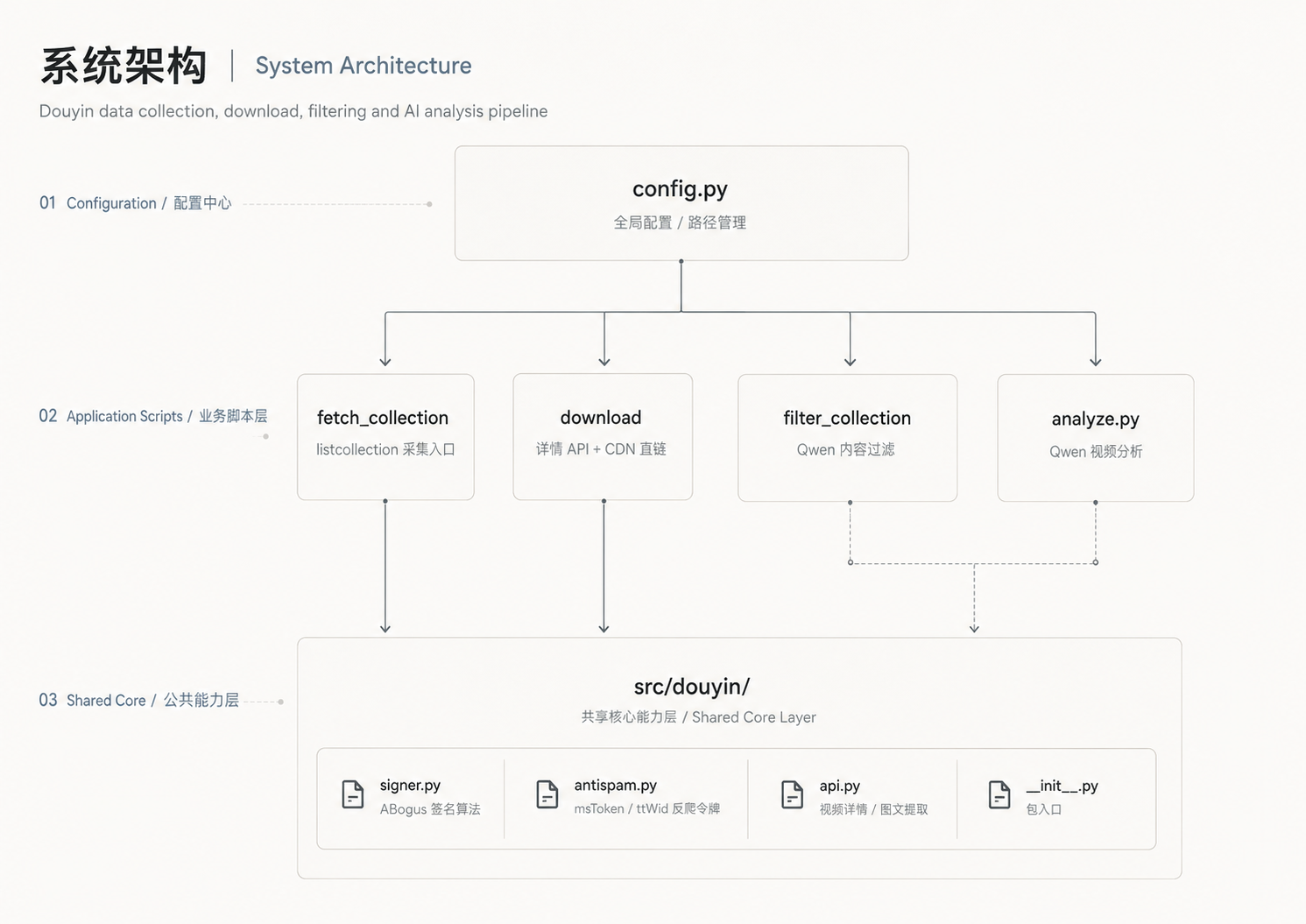
工程分为五个核心模块:
| 模块 | 功能 | 关键技术 |
|---|---|---|
fetch_collection.py | 全量爬取抖音收藏列表 | ABogus 签名、msToken/ttWid 反爬令牌 |
filter_collection.py | AI 判断视频是否与求职/职场相关 | Qwen 多模态(标题 + 封面图) |
download.py | 无水印视频下载 | 抖音 Web API 直链 + yt-dlp 回退 |
analyze.py | 逐帧分析提取结构化信息 | ffmpeg 抽帧 + Qwen 视觉模型 |
src/douyin/api.py | 封装抖音详情 API | 视频 CDN 提取、图文笔记识别 |
技术难点与解决方案
1. 抖音反爬:ABogus 签名算法
抖音 Web API 对所有请求强制要求 a_bogus 签名参数。这是一个基于 SM3 国密哈希 + RC4 加密 + 浏览器指纹的自定义签名算法。
实现方案参考了 TikTokDownloader 的逆向工程,完整复现了签名流程:
- SM3 哈希:对 URL 参数和方法名分别计算 SM3,作为签名的输入因子
- RC4 加密:使用随机密钥对序列化数据进行流式加密
- 浏览器指纹:生成屏幕分辨率、平台信息等伪指纹数据参与签名
- 动态 msToken:向字节跳动 MSSDK 动态获取反爬令牌,请求失败时回退到随机生成
# 签名生成入口
abogus = ABogus(DOUYIN_USER_AGENT, "MacIntel")
params["a_bogus"] = abogus.get_value(params, "POST")2. 无水印下载:从 Playwright 到 API 直链
版本 1(已废弃):使用 Playwright 启动浏览器打开视频页面,等待 <video> 标签加载后提取 src 属性。痛点:
- 启动浏览器开销大,单链接下载需 5-10 秒
- 受 DOM 结构变化影响,抖音更新后常失效
- 图片笔记无法提取原始分辨率
版本 2(当前):直接调用抖音详情 API /aweme/v1/web/aweme/detail/,从响应中解析 bit_rate 列表,按分辨率、FPS、码率排序取最高画质 CDN 地址。Web 端返回的地址天然无水印。
def extract_cdn_url(detail: dict) -> str | None:
bit_rate = detail["aweme_detail"]["video"]["bit_rate"]
# 按 max(h,w), fps, bitrate, data_size 排序
scored.sort(key=lambda x: (x[0], x[1], x[2], x[3]))
return scored[-1][4] # 最高画质 URL效果对比:
| 指标 | Playwright 方案 | API 直链方案 |
|---|---|---|
| 单视频耗时 | 5-10s | 0.3-2s |
| 成功率 | ~50% | ~98% |
| 图文笔记 | 模糊截图 | 原始高清图片 |
| 资源占用 | 浏览器进程 | HTTP 请求 |
3. Qwen 多模态分析
分析环节是整个系统最”烧钱”的部分。每条视频需要将帧图片(最多 30 张)和可选的音频转录文本发送给 Qwen 视觉模型:
- 自适应抽帧:根据视频时长动态调整抽帧密度(≤60s: 3s/帧,≤180s: 5s/帧,>180s: 10s/帧),平衡分析质量和 Token 消耗
- 结构化输出:通过 JSON Schema 约束模型输出,确保提取到 10+ 维度信息(企业名、岗位名、薪资数据、投递渠道、方法论等)
- 断点续传:每条视频分析完成后写入
{video_id}.json,中断重跑时自动跳过已完成项 - 并发控制:
ThreadPoolExecutor+MAX_CONCURRENCY=3,避免触发 API QPM 限流 - 模型自动切换:当主模型用量耗尽时,按顺序自动切换备用模型(qwen3.5-plus → qwen3.5-omni-plus → qwen3.5-omni-flash-realtime → qwen3.5-omni-plus-realtime)
实际运行数据:187 条视频,qwen3.5-plus 完成 90 条,评分分布 5 分 10 条 / 4 分 35 条 / 3 分 22 条,平均评分 3.2。
4. Smart Filter:前置过滤降低 Token 消耗
在下载和分析之前,先进行一次轻量级过滤——仅用标题和封面图(单张小图),让 Qwen 判断视频是否与求职/职场/AI 技术相关。
单次过滤的 Token 消耗约为分析的 1/50,但可以筛掉 ~74% 的无相关视频(实际运行:734 条收藏 → 190 条保留)。
数据流
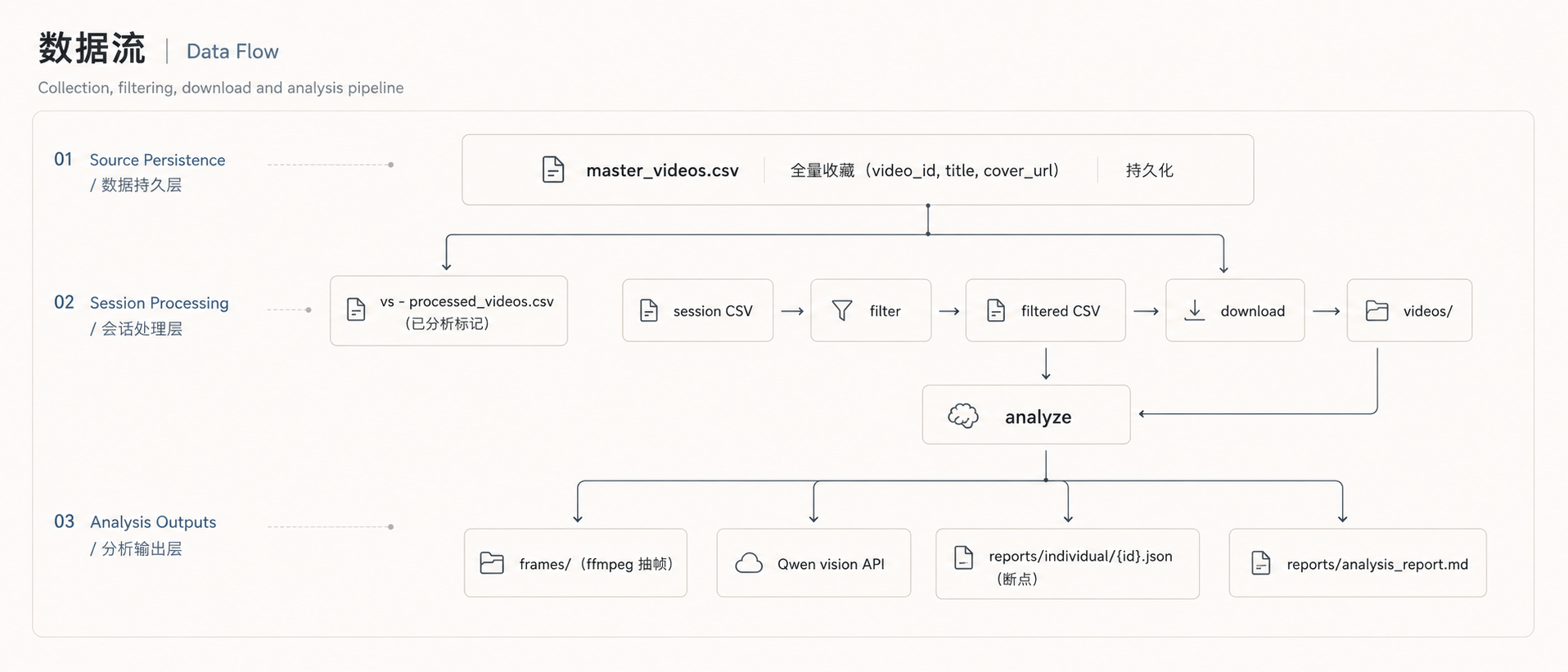
全流程分为四个阶段,每个阶段都支持断点续传:
1. 采集:分页调用 listcollection API,ABogus 签名反爬,去重写入 master_videos.csv
2. 过滤:读取 session CSV,调用 Qwen 多模态,封面图 + 标题 → {relevant: bool, reason: str},写入 filtered_{session}.csv
3. 下载:调用详情 API 获取无水印 CDN → HTTP 直链下载 → ffprobe 校验 → 失败回退 yt-dlp
4. 分析:ffmpeg 抽帧 → Qwen 视觉逐帧分析 → JSON 结构化输出 → 生成 Markdown 报告 → 标记已处理
工程实践
测试驱动开发
项目包含 100 个测试用例,覆盖所有核心模块:
tests/
├── test_analyze.py # 30 用例 — JSON解析、抽帧、API调用、报告生成
├── test_api.py # 25 用例 — 视频详情、CDN提取、图文识别
├── test_filter.py # 16 用例 — CSV解析、Qwen调用、断点
├── test_download.py # 11 用例 — URL读取、视频校验、下载策略
├── test_fetch.py # 8 用例 — API调用、去重、增量追加
├── test_run.py # 8 用例 — CLI参数、步骤串联、异常处理
└── test_config.py # 7 用例 — 参数验证、日志初始化运行方式:
python -m pytest tests/ -v # 全部通过,100/100配置管理
所有敏感信息通过 .env 文件管理,.env.example 作为模板开源。配置项包括 API Key、模型选择、并发数、抽帧密度等,均可通过环境变量覆盖。
QWEN_API_KEY=sk-xxx # 阿里云百炼 API Key
QWEN_MODEL=qwen3.5-plus # 默认模型(支持自动切换)
DOUYIN_COOKIE=xxx # 抖音登录 Cookie
MAX_CONCURRENCY=3 # 分析并发数
ENABLE_FILTER=true # 启用前置过滤模型自动切换机制:当主模型 API 调用失败(如用量耗尽)时,系统会按以下顺序自动切换备用模型:
qwen3.5-plus(默认)qwen3.5-omni-plus-2026-03-15qwen3.5-omni-flash-realtime-2026-03-15qwen3.5-omni-plus-realtime
每个模型最多重试 3 次,失败后自动切换到下一个,确保分析任务不会因单个模型限流而中断。
项目地址
开源仓库:github.com/8BitcloudBot/sv2text
欢迎 Star、Issue 和 PR。